Load testing for production-readiness - taking Grafbase for a spin
We’re big fans of load testing here at Artillery, so when the team over at Grafbase floated the idea of running some real-world load tests on their service we did not need much convincing.
We also decided to take it one step further, and not just run some load tests on Grafbase, but also use these tests to show a common real-world scenario of when load testing is employed - load testing potential dependencies to evaluate their performance.
Read on to see:
- How easy it is to run a distributed production-grade load test on a GraphQL API with Artillery
- How Grafbase can help you build a GraphQL API, and what baseline performance and scaling looks like on the free tier
- An example of how load testing can help with production-readiness reviews
What is Grafbase?
Grafbase is an end-to-end platform for building GraphQL APIs. It’s an alternative to services like AWS AppSync and Hasura, with a focus on providing a full-stack solution with modern DX:
- A globally-distributed serverless API gateway
- An edge-optimized caching layer
- Built-in database, authentication, full-text search, analytics, and lots more
What are we going to do here?
In this blog post we’re going to imagine that we’re a team at Acme Corporation and that we’re considering building a new production service on top of Grafbase.
Let’s imagine we’ve already built and deployed a proof-of-concept “Acme News” app on top of Grafbase, and that we’re excited about the improvements in developer productivity we experienced. Now comes the next stage - evaluating what running this service in production may look like.
The application: Acme News
Acme News is an app that allows users post links to articles, and upvote and comment on those links. It’s based on the official BaseNews example from Grafbase.
The schema file we used to deploy the backend service to Grafbase can be found here: https://github.com/hassy/grafbase-load-testing/tree/main/grafbase .
You can follow the quickstart guide to deploy your own instance of the service using the free plan on Grafbase.
What does it take to be production-ready?
Production-readiness is a complex subject. Some of the common performance-related areas that need to be covered usually include:
- Implementing & verifying monitoring & logging
- Defining SLIs, SLOs, and SLAs
- Verifying load balancing, autoscaling and failover behaviors
- Verifying performance under load
- Right-sizing infrastructure
- Writing & testing runbooks for common failure scenarios
- Documenting on-call policy for the new service
Load testing is a very versatile tool to have in your toolbox when it comes to getting production-ready, and can be employed to help verify and meet many of the performance-related requirements of a production-readiness checklist:
- Load testing can be used to test and verify load balancing and autoscaling behaviors of the service and underlying components
- Load testing can help verify that monitoring & alerting is set up and functioning as expected
- Load testing can help rightsize infrastructure requirements such as Kubernetes pod CPU and memory allocations, or Lambda function memory sizing
- Load tests can act as guardrails around SLOs and help verify that they’re met under high load
All of those start with creating and running initial loads test to verify the baseline performance characteristics of a service. That’s the part we’ll focus on in the rest of this blog post.
Load testing GraphQL
Load testing a GraphQL service is similar to testing a typical RESTful service for the most part, with only a few minor GraphQL-specific differences.
The two most important considerations for load testing any service are:
- Making sure to create a realistic load pattern on the service
- Using a realistic workload definition
Creating a realistic load pattern
Synthetic traffic created with load tests needs to emulate the shape of traffic that your service experiences in the real world. As a general rule we recommend running either spike tests or soak tests, as those tend to provide the best ROI.
For this investigation we will emulate a sudden traffic spike, to see how our service would deal with a sudden influx of traffic over a short period of time. Spike tests tend to put a lot of pressure on autoscaling components and behaviors of the underlying system, and we’d like to check that Grafbase can take care of it for our “Acme News” app, as we’re expecting our traffic patterns to be very spiky as news stories break and go viral.
Defining a realistic workload
We also need to make sure that the workload itself is representative of real-world use. For our investigation we are going to emulate a read-heavy workload. We expect 90% of our app’s users to simply browse through existing content posted by other users (in line with the 90-9-1 rule ) and that’s where we’ll start with our performance evaluation.
A note on testing GraphQL
Everything is always “200 OK” in GraphQL. Errors are communicated in the JSON payloads sent back to the client, and HTTP codes are not used in the same way as in RESTful services. This means we cannot rely on HTTP status codes to check whether requests are successful or not.
Our Artillery script is using the built-in expect plugin with JMESPath expressions to check that the requests to the service are successful:
- post:
url: '/graphql'
name: Get posts
expect:
- jmespath: 'data != null'
- jmespath: 'errors == null'This makes sure that the data field is not null, and there are no errors for a request to be considered successful.
Test setup
We’ve deployed our “Acme News” app to Grafbase in the eu-west-1 region, and that’s what we’ll be using as a target for our tests.
The database of posts has already been populated with realistic data, to allow us to load test our read-only workload. We’re using the free Hobby plan for these tests.
Our Artillery test definition can be found here . We’ll be using Artillery’s built-in AWS Lambda support to run a distributed load test from two different AWS regions: eu-west-1 and us-east-1 to see if performance varies depending on where user traffic originates.
Our base load pattern is as follows:
- We start by emulating a baseline of traffic to our service, with 10 users arriving to use our service every second for 3 minutes
- The next phase also lasts 3 minutes, but we ramp load up from 10 to 20 new users per second
- The third phase is the traffic spike, where we increase the load by 2.5x over 2 minutes, and go from 20 to 50 new users per second
We will be running these load tests with 10 Lambda workers, effectively multiplying the base figures by 10, i.e. we will be creating 500 new users per second by the end of the test run.
What results should we expect?
Before running any tests, it can be helpful to formulate some expectations and hypotheses which will be disproven or supported by the results of our load tests.
As we’re testing a read-only workload, we should expect Grafbase to be able to cache responses very efficiently (and help us solve one of GraphQL’s biggest performance problems ).
Our application is deployed to eu-west-1, but one of Grafbase’s features is seamless global deployments. As such, since we’re testing a read-only workload, we should expect the response times to be very similar regardless of which region we’re sending traffic from.
Finally, like many other serverless solutions, we may see Grafbase exhibiting cold start behavior . We’ll be looking out for spikes in max latency reported near the beginning of the test, and near the beginning of the final load phase for an indication of cold starts.
Running the tests
We will run our test as follows:
artillery run:lambda -e prod --region eu-west-1 --count 10 artillery/acmenews-read.yml --record --key $ARTILLERY_KEYThis command will run our test script using 10 AWS Lambda functions in eu-west-1. We’re also setting --record and --key flags to have the results recorded to the Artillery Cloud dashboard for analysis.
We will run a test in two different regions: eu-west-1 and us-east-1 to compare performance with traffic originating from two different regions.
Test Results
First test - running from eu-west-1
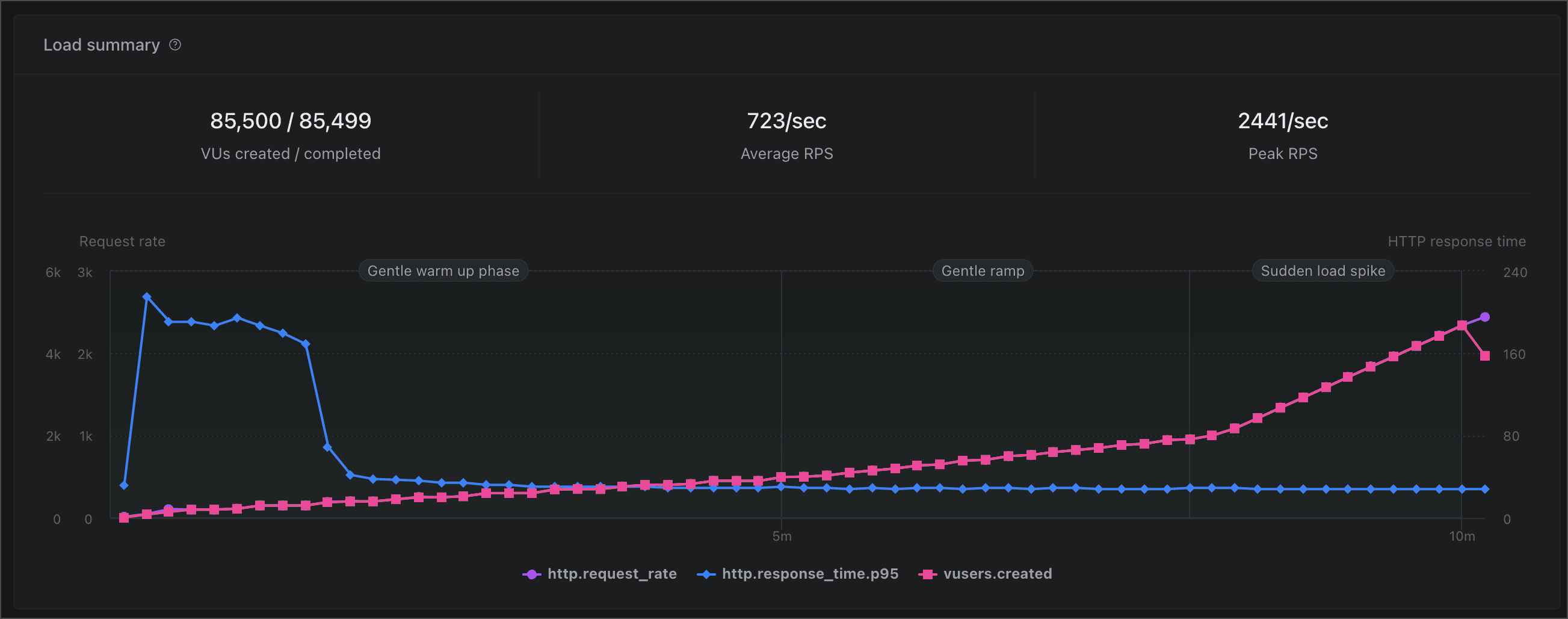
We ran our first test from eu-west-1. The summary of the load test is below:
- The test completed successfully, with a total of 85.5k virtual users created over a ~10m period
- The app served 2441 requests per second at peak
- p95 of the response time is between 27-30ms throughout the test run, even as load starts to ramp up at around the 6m mark and peaks at the 9m mark

p99 is similarly very stable and stays in the 38-41ms range throughout the entire test run. We can see a couple of outliers if we plot max response time but
those aren’t really a cause for concern as p99 is both low and stable throughout the test. We can reasonably assume that we did not see a cluster of slower
requests happening in close proximity to each other which would require a further investigation. As-is, the outliers are likely to be caused by network
latency.
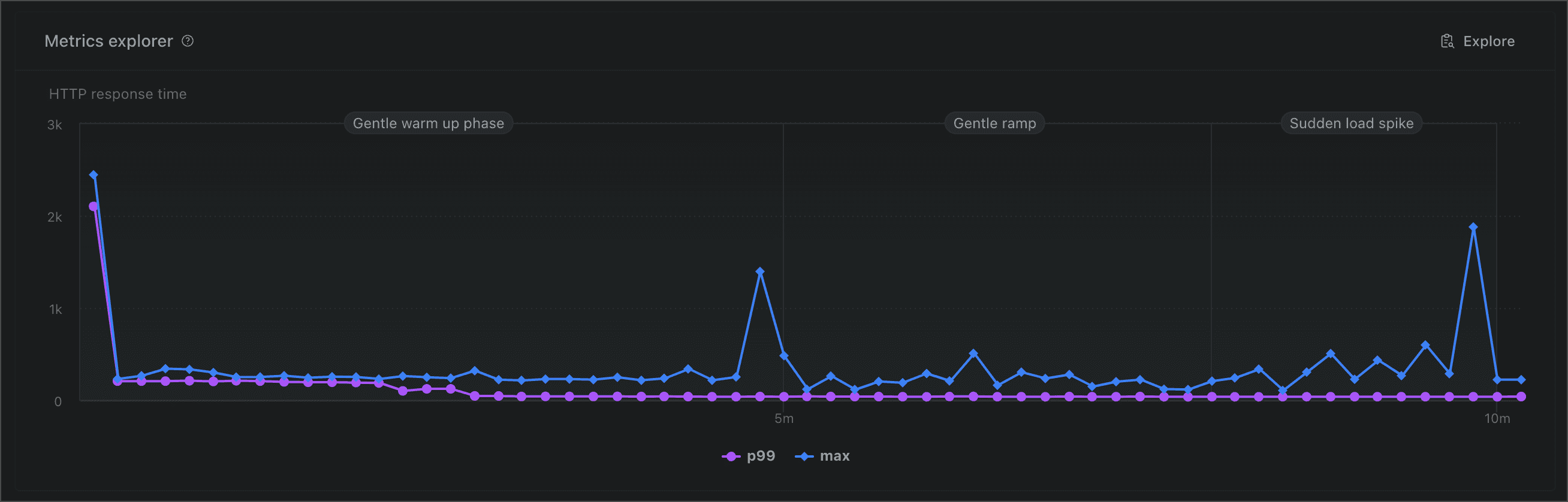
The results of this test confirm one of our earlier hypotheses: Grafbase is caching responses efficiently, as evidenced by the steady response time even as load increases.
The initial “hill” of p95 latency looks odd but is not enough to confirm whether it’s the result of a cold start, as it drops very quickly (in less than 30 seconds).
Second test - running from us-east-1
We will now re-run the same test from us-east-1, to see whether the origin of user traffic affects response times.
The main thing we’re looking for here is the difference in p99/p95 response times between this test and the previous one for an indication of whether the global edge cache worked as expected.
And well, look at that - just as expected. We are getting almost the same latency numbers for traffic originating in us-east-1, as expected with a working edge cache.
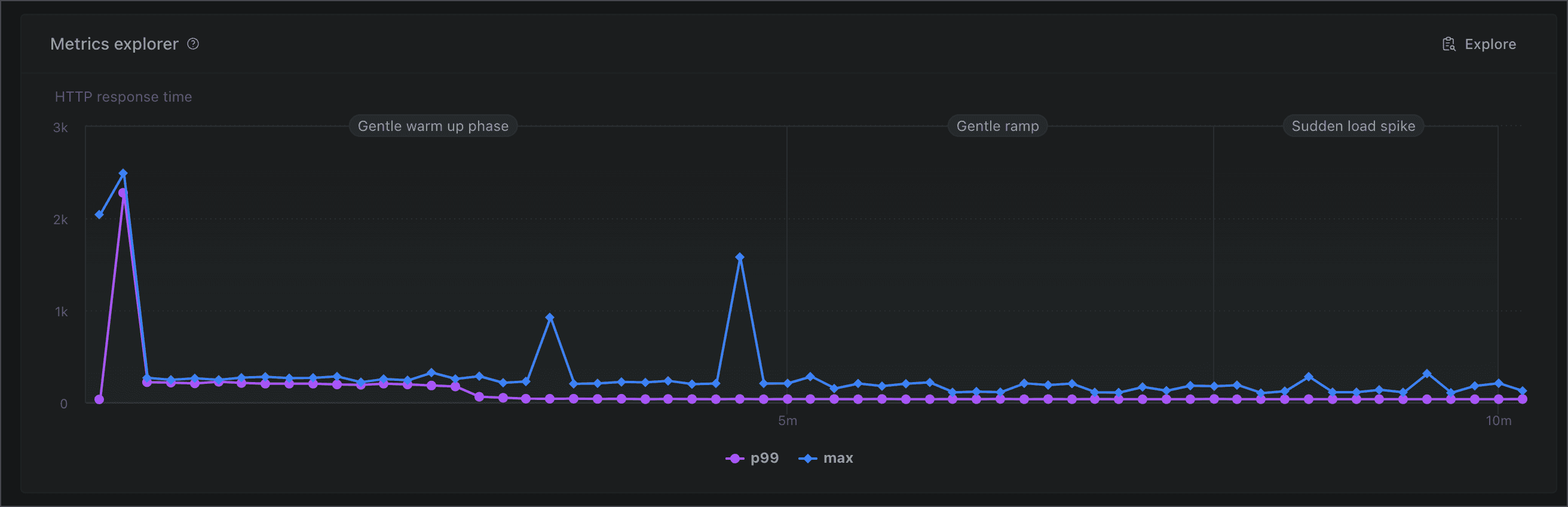
Wrapping up
Our initial load tests helped us verify our hypotheses about the performance of Grafbase. At this point, the Acme News team has a couple of options:
- Extend our load testing scripts to exercise other parts of Grafbase that Acme News is going to depend on. For example:
- We may want to mix some write/update scenarios into our test to emulate a small percentage of users posting new items. This would let us evaluate the performance of the built-in database offered by Grafbase.
- We may have another existing GraphQL service that we may want to expose via Grafbase to take advantage of its edge-optimized caching layer.
- Scale out our load tests further to check the performance of Grafbase at our eventual projected production load. This would give us the information we’d need for the Scaling & Performance part of our future production-readiness review.
- Set up more automated checks of test results to enable us to start running these tests as part of our CICD pipelines, as load tests or synthetic tests.
Happy load testing!